

Introduction
In Data Engineering first thing we need to do is connect and extract data from a data source. The data sources can be of many types, like:
- Relational Databases (E.g. Oracle, PostgreSQL, MySQL etc.)
- NoSQL Databases (E.g. MongoDB)
- Files (E.g. csv, parquet, avro, xls files)
- APIs
- Web scraping
Let's work on integrating a PostgreSQL Database with python. You can connect to data using various tools and packages. We will explore some of the ways to connecting the data, like:
- psycopg2 (Python PostgreSQL Database adapter)
- SQLAlchemy (Python SQL toolkit)
- Pyspark (Python API for Spark)
Creating a PostgreSQL Database using Supabase
In this example, we will be using a open source PostgreSQL database provided by Supabase instead of installing PostgreSQL database in local machine.
- Go to Supabase
- Create an account
- Create a project
- GO to SQL Editor and create a table in the DB with some example data.
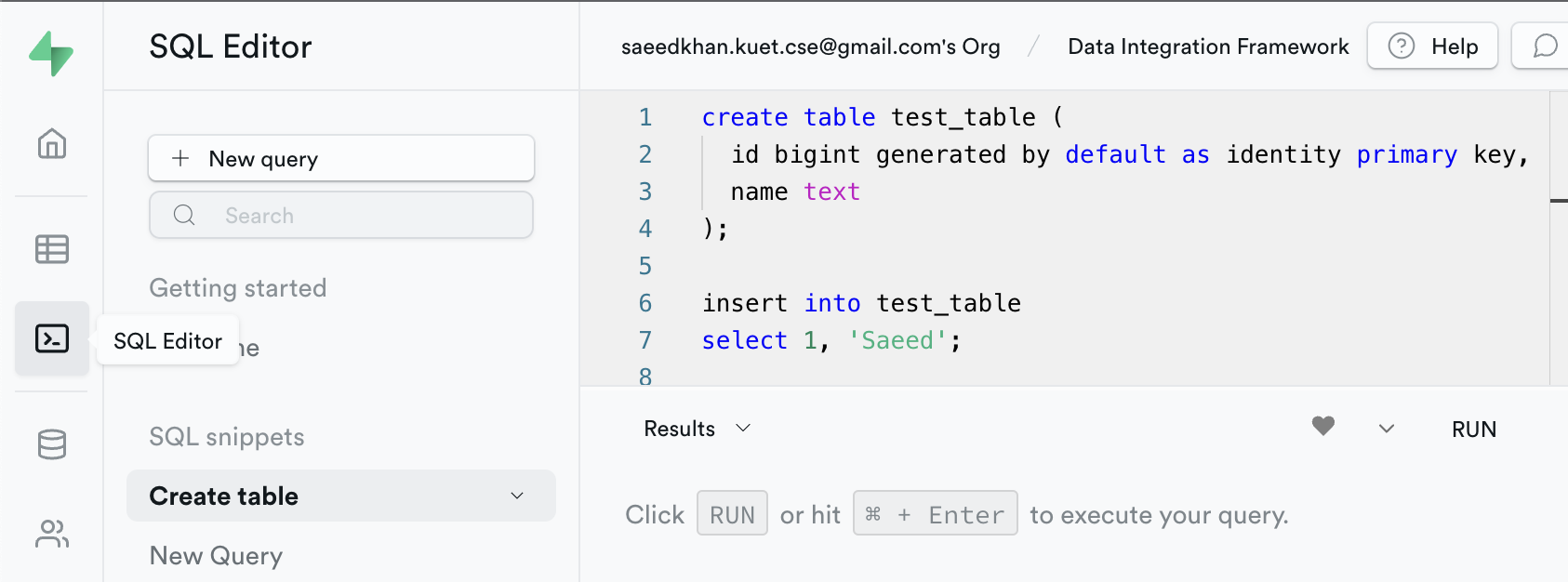
Example code:
create table test_table (
id bigint generated by default as identity primary key,
name text
);
insert into test_table
select 1, 'Saeed';
commit;
- We will get all the necessary information about the database in the settings. (E.g. Reference ID, username, password, db name, port, connection string etc.)
Connecting to Data using Python
1. psycopg2 (Python PostgreSQL Database adapter)
Steps:
install psycopg2
- Run the following command to install psycopg2
pip install psycopg2-binary --user
Read Data
- Connect with Database with the following code and test connection.
import psycopg2
connection = psycopg2.connect(
host="your host name from supabase",
database="postgres",
port="5432",
user="postgres",
password="your password from supabase")
cursor = connection.cursor()
# Execute a query and get data
cursor.execute('select * from test_table')
data = cursor.fetchall()
print(data)
Output:
[(1, 'Saeed')]
Write Data
- We can also insert some data in the database using the connection.
insert_query = "insert into test_table (id, name) values (%s,%s)"
cursor.execute(insert_query, (2, 'Khan'))
connection.commit()
cursor.execute('select * from test_table')
data = cursor.fetchall()
print(data)
Output:
[(1, 'Saeed'), (2, 'Khan')]
2. SQLAlchemy (Python SQL toolkit)
Steps:
install sqlalchemy
- Run the following command in terminal to install sqlalchemy.
pip install SQLAlchemy
Read Data
- Run the following code to test connection & extract data with SQLAlchemy.
import sqlalchemy
db_password = "Your Supabase db Password"
db_reference_id = "Your Supabase reference id"
db_url = f'postgresql://postgres:{db_password}@db.{db_reference_id}.supabase.co:5432/postgres'
engine = sqlalchemy.create_engine(db_url)
metadata = sqlalchemy.MetaData(bind=None)
table = sqlalchemy.Table(
'test_table',
metadata,
autoload=True,
autoload_with=engine
)
stmt = sqlalchemy.select([
table.columns.id,
table.columns.name
])
connection = engine.connect()
results = connection.execute(stmt).fetchall()
print(results)
Output:
[(1, 'Saeed'), (2, 'Khan')]
Write Data
- To load data into DB using SQLAlchemy we can execute the following example code.
insert_stmt = table.insert().values(id=3, name='Anwar')
connection.execute(stmt)
print(connection.execute(stmt).fetchall())
Output:
[(1, 'Saeed'), (2, 'Khan'), (3, 'Anwar')]
Pyspark (Python API for Spark)
Steps:
Install pyspark
- Run the following command in terminal to install pyspark
pip install pyspark
Install Java
- If you do not have java installed, install java from here
Download JDBC Driver
- Download PostgreSQL JDBC Driver (jar file) from here
Add the driver to Spark classpath
- Go to terminal. Execute the following command to start spark shell.
% spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://192.168.0.102:4040
Spark context available as 'sc' (master = local[*], app id = local-1674349254218).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.3.1
/_/
Using Scala version 2.12.15 (Java HotSpot(TM) 64-Bit Server VM, Java 19.0.1)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
- Now add the path to the PostgreSQL JDBC driver jar file to spark Class path.
scala> :require /path/to/postgresql-42.5.1.jar
Added '/path/to/postgresql-42.5.1.jar' to classpath.
scala> import java.util.Properties
import java.util.Properties
Get the JDBC URL for supabase DB
- Go to Supabase
- Go to your created project
- Go to Project Settings > Database > Connection String
- Select the JDBC connection string and save
Now connect with data using Pyspark
- Run the following code to test the connection using pyspark
from pyspark.sql import SparkSession
import traceback
jdbc_url = "JDBC Connection String from Supabase DB"
# Create SparkSession
spark = SparkSession.builder \
.appName('spark_jdbc_connection_example') \
.getOrCreate()
# Read table using jdbc()
dataframe_postgresql = spark.read.format("jdbc") \
.option("url",jdbc_url) \
.option("dbtable","test_table") \
.option("driver", "org.postgresql.Driver") \
.load()
# Show table data
dataframe_postgresql.show()
Output:
+---+-----+
| id| name|
+---+-----+
| 1|Saeed|
+---+-----+
Our Amazing Sponsors
 View Website
View Website
 View Website
View Website
 View Website
View Website
Comments (0)