


Did you ever find yourself in a situation where you had a directory full of images and might have potential duplicates? To look through each image and mark duplicates will be a waste of your time, and so, you wanted to automate it with a script. But then, a few hours into it, you are reading some OpenCV documentation and articles and you didn’t know how you ended up there and worse, you realize, the rabbit hole is endless.
If the above situation sounds familiar, then this article is essential for you. If not, you will learn a neat trick with Node.JS that you could use when a situation demands it. So, without further ado, let’s look at how we could compare images and detect duplicates using Node.JS by applying perceptual hashing (pHash) and using the Map data structure.
The Process:
The process that we will be following is simple:
- Read all files in the directory one by one.
- Generate unique fingerprints for images using perceptual hashing technique.
- Maintain a Map with the hash as the key and the array of image paths as the values.
By this way, if a key in the map has more than one items in the array, then those images are duplicates. From here, you could do whatever you want with the duplicates.
The Implementation:
Now, let’s look at the code:
The Hash Function:
In order to perform the perceptual hashing of an image, we use the Blockhash library, which implements a variation of the perceptual image hashing algorithm.
So our hash function is as follows:
const fs = require("fs");
const blockhash = require("blockhash-core");
const { imageFromBuffer, getImageData } = require("@canvas/image");
async function hash(imgPath) {
try {
const data = await readFile(imgPath);
const hash = await blockhash.bmvbhash(getImageData(data), 8);
return hexToBin(hash);
} catch (error) {
console.log(error);
}
}
function readFile(path) {
return new Promise((resolve, reject) => {
fs.readFile(path, (err, data) => {
if (err) reject(err);
resolve(imageFromBuffer(data));
});
});
}
function hexToBin(hexString) {
const hexBinLookup = {
0: "0000",
1: "0001",
2: "0010",
3: "0011",
4: "0100",
5: "0101",
6: "0110",
7: "0111",
8: "1000",
9: "1001",
a: "1010",
b: "1011",
c: "1100",
d: "1101",
e: "1110",
f: "1111",
A: "1010",
B: "1011",
C: "1100",
D: "1101",
E: "1110",
F: "1111",
};
let result = "";
for (i = 0; i < hexString.length; i++) {
result += hexBinLookup[hexString[i]];
}
return result;
}
As seen in the code above, the hash function calls a readFile method that gets the image data and the hashes it using the blockhash utility. the hash will be in hexadecimal format. I wrote a utility method to convert it to binary to perform a hamming distance calculation on it. you can skip the binary conversion part if you like.
 View Website
View Website
 View Website
View Website
 View Website
View Website
Read All File Names From Directory:
const fs = require("fs");
const imgFolder = "./img/";
async function getFileNames() {
return new Promise((resolve, reject) => {
fs.readdir(imgFolder, (err, files) => {
if (err) reject(err);
resolve(files);
});
});
}
With the above code, we will be getting an array with the image file names when the promise resolves. for the sake of simplicity, we assume that our directory contains just images.
Generate An In-Memory Map:
const refMap = new Map();
async function generateRefMap() {
const files = await getFileNames();
for (let i = 0; i < files.length; i++) {
const imgHash = await hash(`${imgFolder}${files[i]}`);
let valueArray;
if (refMap.has(imgHash)) {
const existingPaths = refMap.get(imgHash);
valueArray = [...existingPaths, `${imgFolder}${files[i]}`];
} else {
valueArray = [`${imgFolder}${files[i]}`];
}
refMap.set(imgHash, valueArray);
}
console.log(refMap);
}
With the above code, we will have an in-memory map with keys as unique hashes and values as an array of paths. Whenever a hash collision occurs, we just append the path causing the collision to the value array of the colliding key.
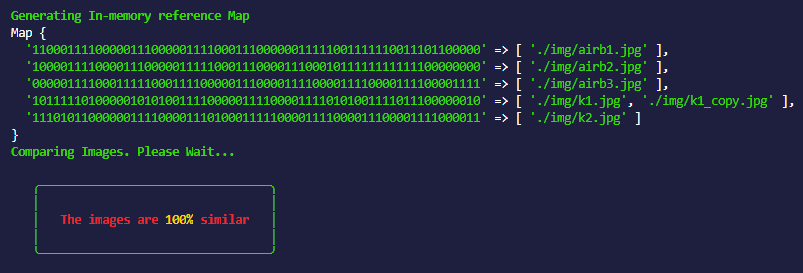
If we piece together all the above parts, we will get ourselves something that would produce the following output:

From looking at the above output, we can conclude that ‘./img/k1.jpg’ and ‘./img/k1_copy.jpg’ are duplicates since they share the same fingerprint.
From here on, we can decide how we’d like to handle duplicates based on the situation and the requirement.
Extras:
Remember that we pointed out an optional hex to binary conversion in the above section? We’ll implement additional functionality to compare two hashes from two images and display what percentage of hash similarities the images share with each other.
Calculate Hamming Distance:
We use a method called hamming distance to calculate the similarity between two hashes. If you’re curious, you can read more about this technique here.
function calculateSimilarity(hash1, hash2) {
let similarity = 0;
hash1Array = hash1.split("");
hash1Array.forEach((bit, index) => {
hash2[index] === bit ? similarity++ : null;
});
return parseInt((similarity / hash1.length) * 100);
}
Compare Hash Similarity:
async function compareImages(imgPath1, imgPath2) {
const hash1 = await hash(imgPath1);
const hash2 = await hash(imgPath2);
return calculateSimilarity(hash1, hash2);
}
The above code will give the hash similarity between the two supplied images in percentage value.
It would be something like the following:
Conclusion:
If you’d like to see a pieced-together implementation of the above code snippets, please have a look at this repo on github.
Thanks for reading my thoughts. Hope you learnt something useful from this article.
cheers :)
Comments (0)