

Overview
Assuming if you are reading this post, you might have interest or finding an effective and reliable approach to do re-indexing on Solr. In this blog, I will talk about an experience and proven approach to Re-building and Re-indexing Solr during production releases, which cuts down our pain from 10-15 days to 1-2 days without impacting any Solr clients and / or end users.
Before deep down, I am assuming you are familiar with Apache SOLR. If YES, you may skip 1st section, else better to go through it and/or deep down with its official documentation
What is SOLR?
SOLR is an open-source enterprise-search platform, written in Java and is widely used for enterprise search and analytics use cases and has an active development community and regular releases.
Apache SOLR is developed in an open, collaborative manner by the Apache SOLR project at the Apache Software Foundation. Its major features include full-text search, hit highlighting, faceted search, real-time indexing, dynamic clustering, database integration, NoSQL features and rich document (e.g., Word, PDF) handling.
SOLR runs as a standalone full-text search server. It uses the Lucene Java search library at its core for full-text indexing and search and has REST-like HTTP/XML and JSON APIs that make it usable from most popular programming languages. Providing distributed search and index replication, SOLR is designed for scalability and fault tolerance.
SOLR’s external configuration allows it to be tailored to many types of applications without Java coding, and it has a plugin architecture to support more advanced customization.
Challenges with Traditional Indexing Approach

SOLR Full Re-Indexing is always a challenge, and it get worsen when data is regularly growing. Building Indexes from scratch in SOLR takes time.
Usually during Production release, the same SOLR server need to respond search queries on other cores and at the same time it has to re-index other cores as well. All these requests are handled under same JVM, shared memory, CPU and other resources of server.
Damn! it puts SOLR service under tremendous load.
Our Amazing SponsorsDigitalOcean offers a simple and reliable cloud hosting solution that enables developers to get their website or application up and running quickly.View Website
Laravel News keeps you up to date with everything Laravel. Everything from framework news to new community packages, Laravel tutorials, and more.View Website
A Laravel Starter Kit that includes Authentication, User Dashboard, Edit Profile, and a set of UI Components. Learn more about the DevDojo sponsorship program and see your logo here to get your brand in front of thousands of developers.View Website
Hence re-indexing SOLR with letting customer uses alive data and flowing through SOLR makes it day tough...... tougher....... toughest job.
So, during production releases single SOLR server (per environment) make its deployment & re-indexing horrible.

Since full re-indexing takes time, the respective core is down and un-responsive until it is completed. In our app, the same SOLR server manages documents for multiple client DBs & organizations. While Production release if SOLR has to re-build and re-index, then it takes around 10-15 days to complete re-indexing. This makes the search page in app (built upon SOLR) down and makes our release team under lot of pressure.
It's Crazy! Who want that long downtime feature, just because of SOLR.
Blue Green Design Approach
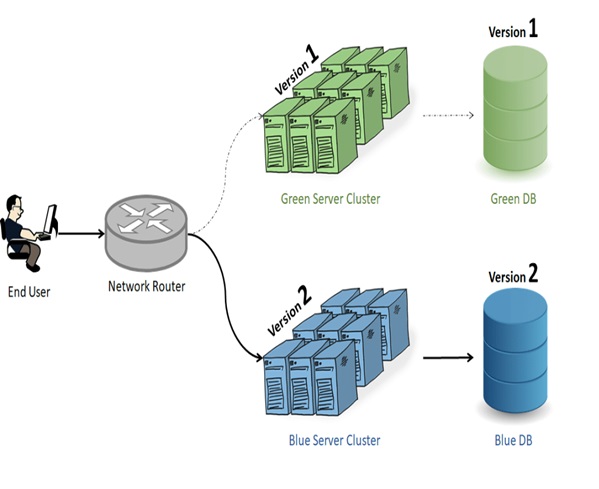
Blue and Green mean two identical Production environments. Which mean, we will have two identical production environment and among those, one will serve the end-user at a time.
Say, we have Production Environment-1 called as Blue and Production Environment-2 called as Green. And All the End User traffic will be routed to Green Environment which is in Version-1.
Then, We Upgrade the Blue environment to Version-2. and perform all sanity and Production Testing to check the installation is correct or not. After that, once after the Production Testing is passed in the Blue environment, we slowly route all the user to the Blue environment which is installed with Version 2.
Hah! Blue Green Design Looks nice but wouldn't it increase cost?
Not Really, because when all traffic is moved to Blue, we can update Green to Version 2 and put any of them down later. If you are using a cloud that would be easy.
SOLR Environment (Single Server)
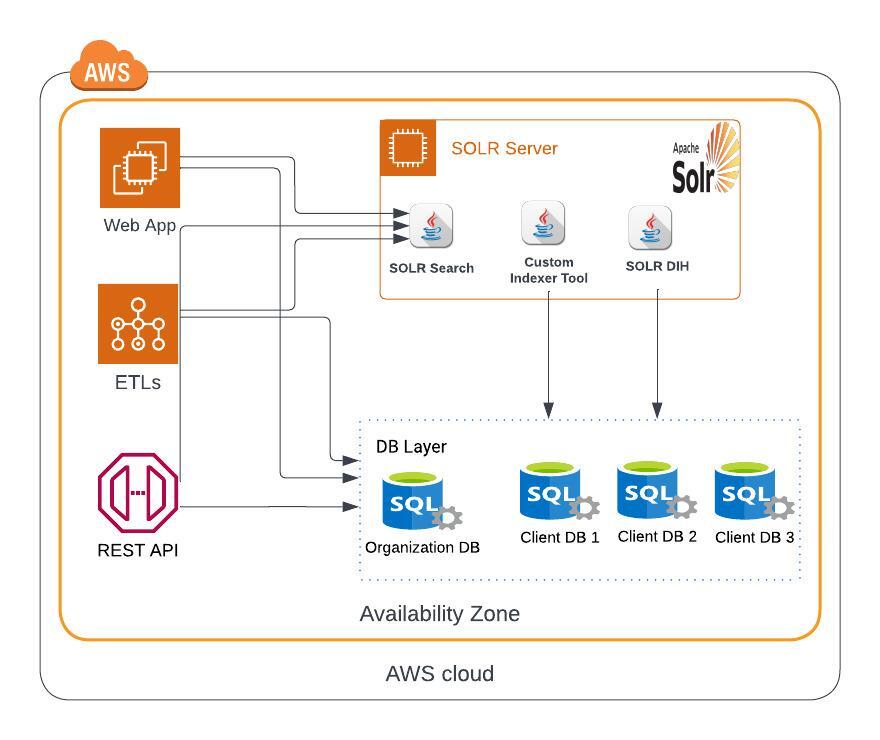
Let's take an example of a sample architecture around SOLR Environment to understand this design. SOLR is deployed on EC2 m/c having some supporting JAVA apps like
- SOLR Search - in-built SOLR service to create / update/ read / delete indexing request.
- Custom Indexer Tool - a custom tool to create / delete core and perform full & delta indexing.
- SOLR DIH - in-built SOLR service to re-index a core.
- Some of modules like WEB App, ETLs & REST APIs interacts with SOLR to create, update, read & delete document's index.
- Each of these modules & SOLR app interacts also with DB Layer.
- multi-tenant application's DB Layer usually have 1 specific DB to manage organization / client meta data and multiple client’s DB respectively.
SOLR Full & Delta Indexing (Blue / Green Server)
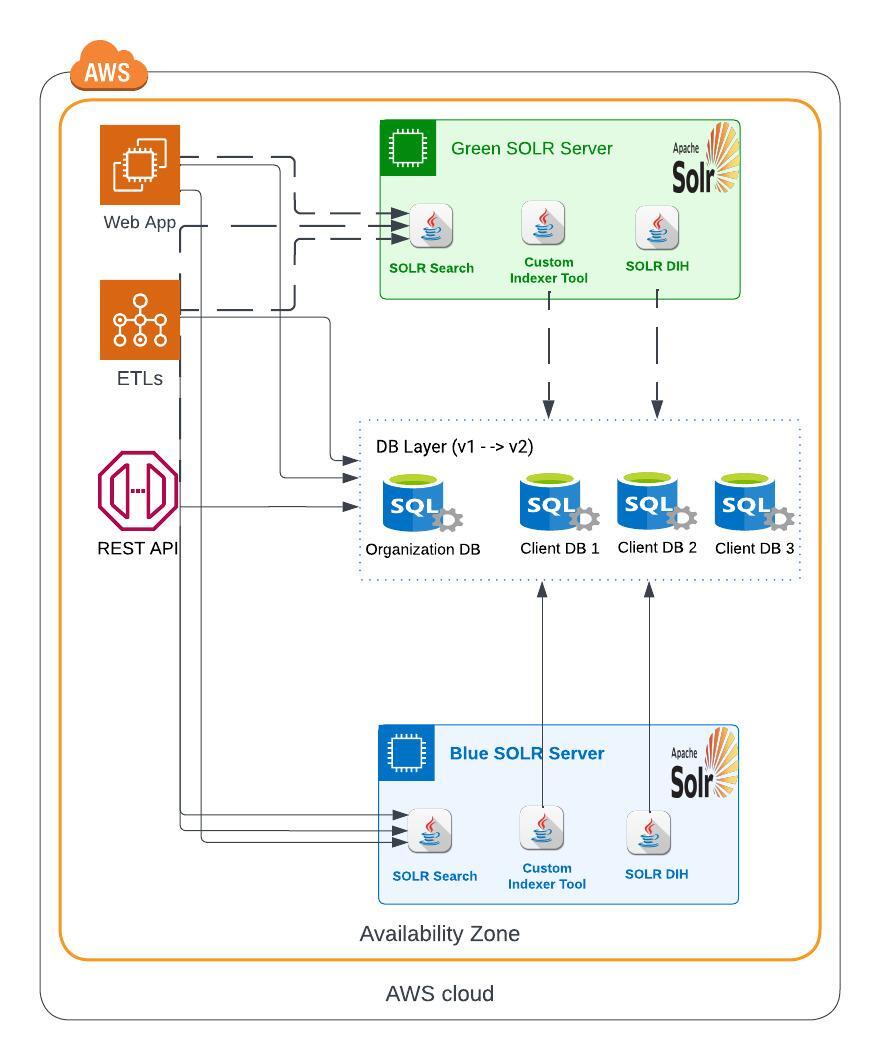
- Following Blue / Green Deployment approach, in Delta indexing a new Blue Solr Server is setup similar as Green Solr Environment.
- Deploy the latest version of Solr Search, Indexer tool & Solr DIH on Blue Solr Server.
- As a part of production release, database may also upgrade to v2, having no breaking changes to other modules and existing Green Solr.
- Start re-building all indexes in advance on Blue Solr Server. The Blue Solr server already contains upgraded version of Solr configuration (if any).
- At the same time modules as Web App, ETLs & REST API interact with existing Green Solr for any CRUD operation on Solr Documents.
Re-building indexes are done Org wise and not for complete system at all in once. Hence as soon as index of one Org is done on Blue Solr, its traffic is redirected from Green to Blue.
- On production release day, mostly all the org’s document are indexed on Blue Solr.
- There can be a case while re-indexing on Blue Solr, some documents are created, updated and deleted on Green Solr.
Wait! here is a catch. There can be some difference (Delta) b/w Green & Blue Solr. These delta indexes need to be reflected on Blue Solr as well.
- Yes, here is the magic of Solr indexer tool. It has feature to identify those delta indexes b/w Blue & Green Solr and capability to sync them.
Delta indexing is also designed to be executed Org wise. As soon as delta indexes are captured in Blue Solr, clients on those orgs are start getting reflected those difference in documents.
- Also, Solr Traffic cut over is designed Org wise as well and can be done just after Full or Delta indexing.
Identify Delta & Sync indexes b/w Blue & Green
Step Back
Hold On! Explain... again how this "Delta" documents came into picture.
Sure! then before going into more details of identifying delta indexes, let's dig down what happen before it. So, after Blue server was setup, full indexing was performed on it. That may have taken long time (maybe days or week). Since other app modules were interacting to Green SOLR, it may have updated some indexes (only on green) after full indexing on Blue.
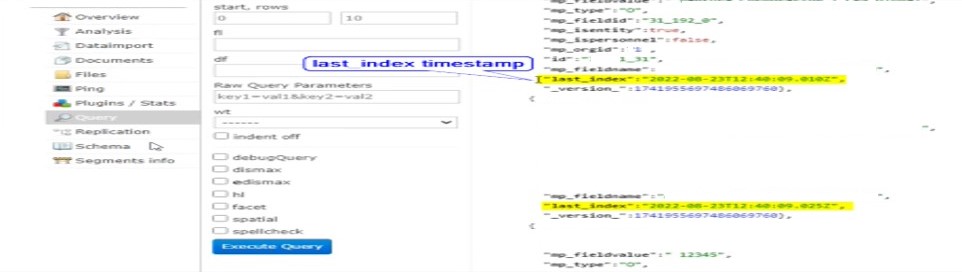
Hence, we need a way to know when full indexing was completed on Blue server. So for this, indexer tool adds a document with id -9999 having timestamp when indexing (full or delta) was completed for a core.

Also, in SOLR's data-config.xml, we can configure a field to have timestamp for each document. This way we can get, when any document was last updated in Solr.
Thought! Wouldn't it be better to cut over traffic as soon as Blue server is Fully indexed? Why to wait to have Delta indexes?
No! Because even during full indexing on Blue server, there is still a chance any document got updated on Green Solr via app's module.
Let's Dig Down Actual Design
Ok, now let's come back on what are the steps to identify delta documents for given core b/w Blue & Green Solr. I have tried to explain the solution of delta indexing with below sequence diagram. Let's dig into this.
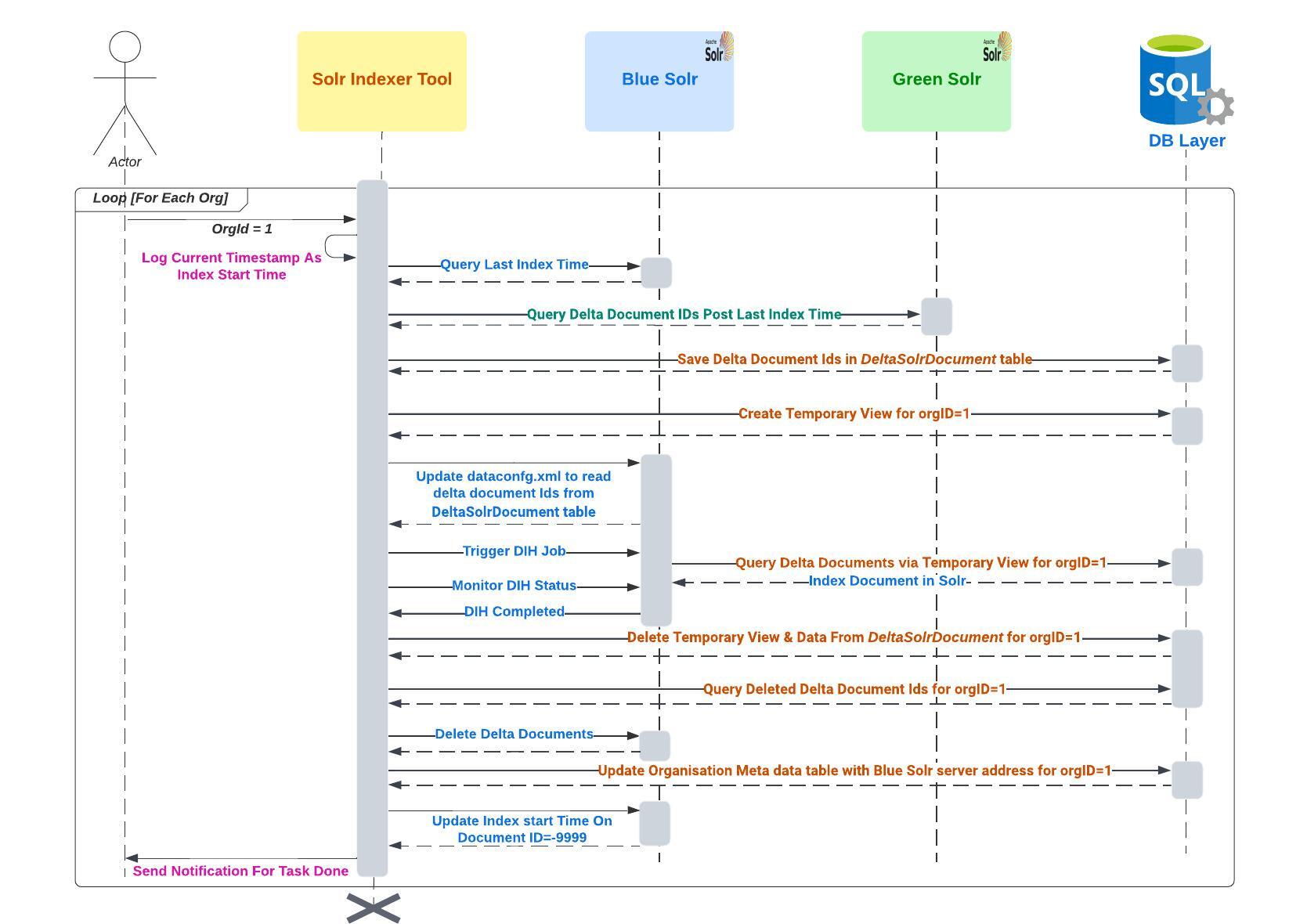
Under Solr, a property last_index of type timestamp has to be maintained under each document, which is updated with system time whenever a document is created / updated. With the help of this field, it can be identified which document were created / updated after a particular time.
- Get the last index time of Blue Solr server for given Organization. (Recall, the last index time is added / updated at the end of every full / delta indexing for ID = -9999)
- Query delta document Ids from Green Solr instance which was updated after last index time collected at step 1.
- Save delta document Ids in DeltaSolrDocument table. DeltaSolrDocument is simple table with 2 columns (orgId, documentId).
- Create temporary View for given Org ID.
Yes, there should be capability to create & delete temporary view on runtime for given Org Id. Might be via a stored procedure.
- Update the dataconfig.xml file of Org's core to use DeltaSolrDocument table & temp view.
- Trigger Solr DIH Job.
- Indexer tool start a thread to monitor the DIH job status.
- Post Solr indexing, delete temp View & data from DeltaSolrDocument table for given Org ID.
- Collect the deleted delta document Ids from client DB.
What? collect deleted document Id from DB? Yes, unfortunately in Solr whatever document is deleted, is deleted at all. There is no way to get what document were deleted after given timestamp. Luckly, we maintained a table from where we were able to identify what document was deleted after given timestamp. So maybe you need to find your own solution, how to identify deleted documents after given time stamp.
- Delete delta documents from Blue Solr server.
What If I don't delete document from Blue server? Well, they will be visible in SOLR search, if this is not an issue, you can skip deleting delta documents.
- If indexing is successful and traffic redirection has to be done then update the Organization meta data table with Blue Solr server address, so application can connect & route requests to Blue Solr server.

Yes! you got it correct. All integrated apps, gets the target Solr URL from Organization meta-data table on each request. You may opt any other solution for traffic redirection like load balancer, routing server, zookeeper, etc. It's just a choice we made as per suitable integrations of other apps.
- If indexing is successful then add / update the document (with id = -9999) for index start time, which can be utilize as the last index time at step 1 in next run of delta indexing.
- A notification email is sent for task completion.
What Do We WIN?

- With Blue / Green Solr Deployment approach, end users can still search the documents from the app during re-indexing.
- Indexing can be done in advance on another server(s) org wise, which enables the possibility that we can index specific org whenever we want and redirect traffic for the same any time.
- Since now not the same server has to respond search queries and perform indexing at same time. Performance of both request (search and re-index) is improved during deployment.
- In recent production releases this approach has been promising and even the time duration of re-indexing has been lower down.
- Now it was able to re-index all Organization within 1-2 days without impacting end users. No pressure at all now.
Finally! We are at end of this blog. Hope I have tried to explain the problem statement and solution. Feel free to comment for any queries or suggestion, I will try my earliest to respond.
Comments (0)