


In the modern world, real-time analytics, machine learning, and smart applications are some of the stand-out technologies that are helping businesses strive forward. And these technologies are backed up with loads of data that can be structured and used to deliver better results and operations.
Extracting a large amount of data from different enterprise aspects is the fundamental aspect for driving innovation and growth.
Data ingestion assists data teams to get data from everywhere into the object store or a landing area where it can be utilized for analytics and ad hoc queries. But why is data ingestion highly important for businesses to move their data? What are different data ingestion types? And how does it work in object storage?
We'll address these questions to help you get a clear view of the topic. So without further ado, let's get started.
What Is Data Ingestion?

Data ingestion quickly moves data from different sources into an object store or landing area for different useful purposes. A data ingestion pipeline is created where the data is consumed from the origin and cleaned before it is moved to the destination point.
 View Website
View Website
 View Website
View Website
 View Website
View Website
The primary capability of data ingestion people is to quickly and seamlessly ingest different types of data like bulk data assets and real-time streaming data from different on-premises storage locations.
Also, structured data is processed and generated by legacy on-premises platforms---data warehouses and mainframes---and even semi-structured and unstructured data like audio, video, graphs, image, and text files.
Depending on the use case of the data, you can use different data ingestion services provided by different software companies, including AWS and IBM, among others.
Why Is Data Ingestion So Important?
You can speed up data availability for achieving business outcomes by focusing on the data ingestion part of the data lifecycle management.
Data ingestion enables the data team to work faster and get the agility and flexibility to scale because of the narrow scope of the data pipeline.
Setting up the parameters enables the data scientist and data analysts to create a single data pipeline and move the data to their destination from the point of origin. It removes the troubles of collecting data sets that can be stored in object storage to be later used for different purposes by different data teams.
Multiple data engineers utilize the data ingestion pipelines to remove the complexities in handling data's scale and business demands. Multiple different intent-drive pipelines can be created and automated across the organization with no team involvement to achieve unprecedented scale to achieve business goals.
Common examples of data ingestion include moving data from salesforce.com to a data house for analysis using Tableau or capturing data from the Twitter data feed for real-time and quick sentiment analysis. Data ingestion can also train different machine learning models for multiple use cases and experimentations.
But that's not all. Multiple uses of data ingestion make it one of the vital components for moving data from the source to the destination.
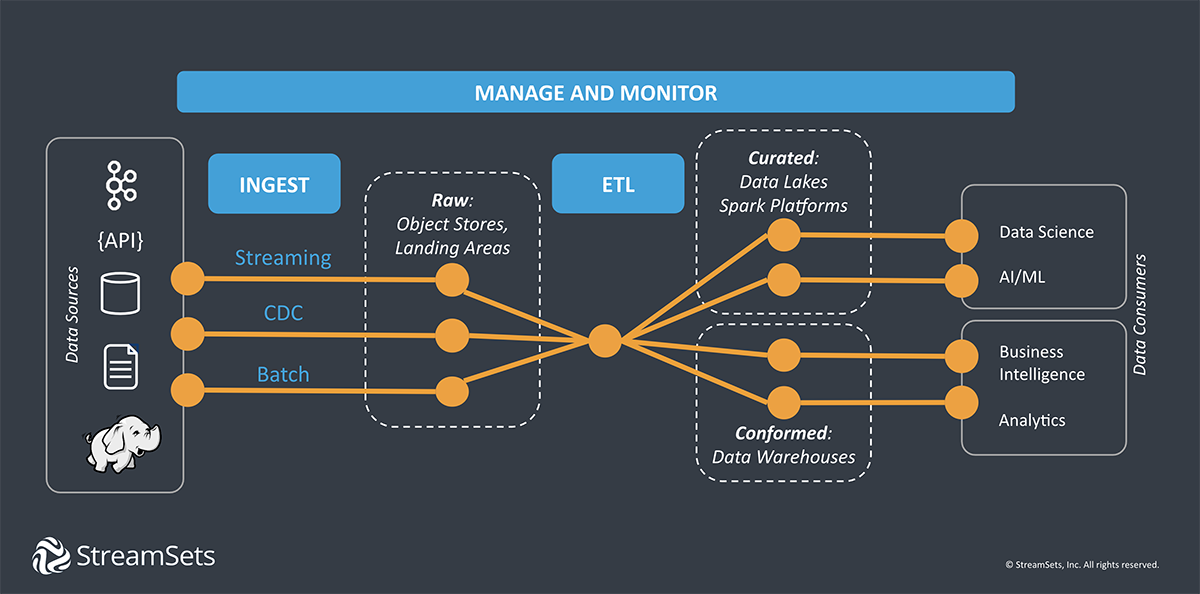
How Does Data Ingestion Work in Object Storage?
The overview of the data ingestion process highlights data extraction from the source and the loading of data in the staging area or destination.
One simple data pipeline applies one or more transformations or data filters before moving the data to the destination. Additional pipes are used for advanced transformations like aggregates, joins, specific analytics, reporting systems, and applications.

{kind=link}
You need to understand different data integration components to get a decent idea about how it works.
Data Sources
Data teams are constantly under pressure to increase the data load from different business units, unstructured destinations, and 3rd party sources. Enterprises are focused on increasing data ingestion in object storage when and where they want it.
Some of the leading data source types are Oracle CDC, JDBC, HDFS, and Apache Kafka.
Data Destinations
The data extracted from the source needs a destination to reach. A data ingestion pipeline sends data to an application or stores ingested data in a data lake for use in data warehouses, NoSQL, or relational databases. Common destination types are Apache Kafka, Amazon S3, Snowflake, JDBC, and Databricks.
Cloud Data Migration
Multiple enterprises are focusing on switching to cloud-based platforms for processing and storing data. Data ingestion workloads have become essential to cloud shift, but some complications may arise from moving data out of silos and into cloud data lakes or warehouses.
Data platforms need to operationalize and automate the what-ifs surrounding the data ingestion in cloud migration to better support the rising demand for reliable and continuous data.
Data Ingestion Challenges
The rise in big data, real-time analytics, cloud computing, and the need for increased data capacity has created multiple data ingestion challenges that need to be handled professionally. Without understanding the downside, you won't be able to find the solution to overcome them.
Complexity
The rise in the complexity of data engineering to-do lists can be a difficult problem for multiple enterprises. Creating an individual data pipeline from scratch for every new data source slows down the efficiency of the data team.
Rework and Maintenance
Performing the same task repeatedly with multiple rounds of debugging and troubleshooting doesn't leave room for innovation and new technologies to create a significant impact.
Time Consuming
Multiple evolutions or changes in the target system increase your data team's work. A lot of the time is spent on break-fix and maintenance of data ingestion.
Now that you are aware of the basics, working, and complexities of data ingestion in object storage, it's time to transform your business operation and data collection process.
Wrapping Up
Data ingestion is a small portion of data integration. It works great for streaming data and can be quickly used with a few changes or as a way to collect data for ad hoc analysis. Data ingestion places the data at a destination where preparation happens as a reaction to downstream needs.
Comments (0)