




TLDR
Ready to dive into data engineering? This blog presents five beginner-friendly projects that will help you gain hands-on experience with real-world data challenges. By working through these projects, you'll develop skills in data processing, analytics, and visualization using popular tools like Apache Kafka, Python, and cloud platforms. These projects are designed to boost your technical expertise, making you job-ready and helping your resume stand out.
Top 5 Data Engineering Projects for Beginners 2024
Are you ready to take your first steps into the world of data engineering? As you begin your journey, hands-on projects are the perfect way to bridge the gap between theory and real-world application. In this blog, we’ve created a list of beginner-friendly data engineering projects that will not only help you master essential tools and technologies but also spark your problem-solving skills.
Ready to roll up your sleeves and build something impactful? Let’s explore the top data engineering projects for 2024 and be job-ready for data engineering roles.
Prerequisites Before Starting the Projects
Before you begin with the data engineering projects, it's essential to have a solid foundation. Here are the key prerequisites:
-
Basic Understanding of Databases
Familiarity with relational and non-relational databases and the ability to write basic SQL queries. -
Proficiency in a Programming Language
Master Python or Java, especially for data manipulation and ETL processes. -
Knowledge of Data Formats
Understanding of common data formats like CSV, JSON, and XML for data ingestion. -
Learn about the Data Processing Tools
Experience with tools like Apache Spark for big data processing and Apache Airflow for workflow management. -
Basic Statistics Skills
Foundational knowledge of statistics, including mean, median, and standard deviation.🤩 Our Amazing Sponsors 👇DigitalOcean offers a simple and reliable cloud hosting solution that enables developers to get their website or application up and running quickly. View Website
Laravel News keeps you up to date with everything Laravel. Everything from framework news to new community packages, Laravel tutorials, and more.
View Website
Laravel News keeps you up to date with everything Laravel. Everything from framework news to new community packages, Laravel tutorials, and more. View Website
A Laravel Starter Kit that includes Authentication, User Dashboard, Edit Profile, and a set of UI Components.
View Website
A Laravel Starter Kit that includes Authentication, User Dashboard, Edit Profile, and a set of UI Components. View Website
View Website
-
Cloud Platform Knowledge (Optional)
Familiarity with cloud services like AWS or Google Cloud for storage and processing. -
Problem-Solving Mindset
A curious and experimental approach to tackle complex problems and apply optimized algorithms to obtain solutions.
Having these prerequisites will prepare you to dive into your data engineering projects successfully.If you find that you're missing any of these skills, you can easily prepare yourself by checking out various data engineering guides available online.
Getting Started with the Projects
Real-time Data Processing System

Project Overview:
This project involves building a system that processes streaming data in real-time. You can use data from social media platforms, IoT devices, or financial markets to analyze trends and patterns as they occur. This project focuses on capturing and analyzing data as it is generated, allowing businesses to respond quickly to changing conditions or emerging trends.
Quick Guide:
- Install and configure Apache Kafka to set up a distributed messaging system for streaming data.
- Create Kafka topics to organize the streams of data you will be processing.
- Develop Spark Streaming applications in Scala or Python to consume data from Kafka topics.
- Implement transformations on the incoming data using Spark to extract relevant information.
- Store processed data in Apache Cassandra or a data warehouse for further analysis.
- Set up Grafana or Kibana to create real-time dashboards that visualize the processed data.
Technologies Used:
- Apache Kafka
- Apache Spark Streaming
- Apache Cassandra or data warehouse
- Scala or Python
- Dashboard tools (Grafana, Kibana)
Skills Learned:
- Stream processing fundamentals
- Real-time analytics implementation
- Event-driven programming concepts
- Fault tolerance and state management in Spark Streaming
- Integration of streaming and batch processing pipelines
Online Price Inflation Analysis
Project Overview:
In this project, you will gather price data from various online sources to analyze inflation trends over time. This analysis is crucial for businesses and economists alike, as it provides insights into market dynamics and consumer behavior.
Quick Guide:
- Access Common Crawl data to obtain web crawling datasets containing product prices.
- Write web scraping scripts using Python libraries like BeautifulSoup or Scrapy to extract price information from e-commerce websites.
- Transform and clean the scraped data, ensuring consistency and accuracy before storage.
- Store the cleaned data in a columnar format such as Apache Parquet or ORC for efficient querying.
- Use Amazon Athena to run SQL queries on the stored data and analyze inflation trends over time.
- Visualize the results using Tableau or Amazon QuickSight to create interactive dashboards showcasing price changes.
Technologies Used:
- Common Crawl for web crawling data
- Python (BeautifulSoup, Scrapy) for web scraping
- Apache Parquet or Apache ORC for data storage
- Amazon Athena for querying data
- Tableau or Amazon QuickSight for data visualization
Skills Learned:
- Data collection from web crawling and scraping
- Data cleaning and preprocessing techniques
- Columnar storage formats and efficient querying
- Calculation of price indices and inflation rates
- Visualization of economic trends and insights
Aviation Data Analysis
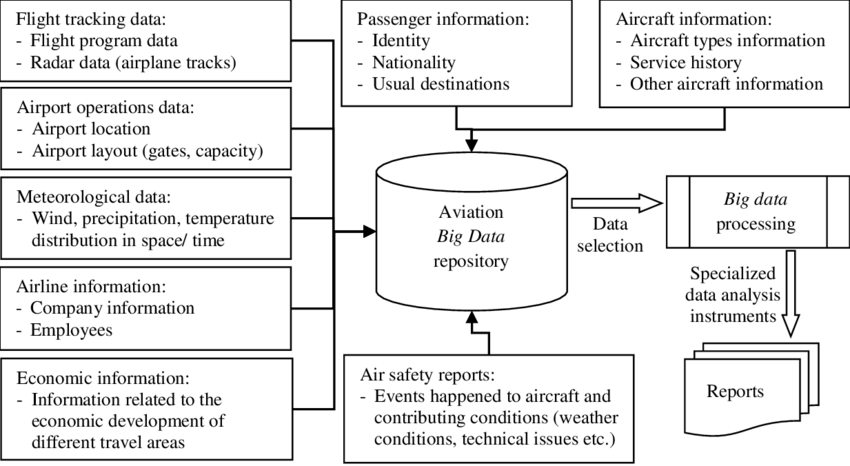
Project Overview:
This project focuses on analyzing aviation data to understand passenger behavior and operational efficiency. It involves collecting streaming data from APIs and performing analytics.
Quick Guide:
- Set up Apache NiFi to automate the ingestion of flight-related data from various APIs.
- Create data flows in NiFi to pull in real-time flight tracking, weather, and airport database information.
- Load the ingested data into AWS Redshift or Google BigQuery for structured storage and analysis.
- Use Apache Hive to write SQL-like queries that analyze flight delays, cancellations, and passenger traffic patterns.
- Perform data transformations as needed to prepare the dataset for analysis.
- Develop visualizations in AWS QuickSight or Tableau to present insights on aviation performance.
Technologies Used:
- Apache NiFi for data ingestion
- AWS Redshift or Google BigQuery for data storage
- Apache Hive for querying data
- AWS QuickSight or Tableau for data visualization
- Flight tracking APIs, weather data feeds, airport databases
Skills Learned:
- Working with APIs for data collection
- Data cleansing and transformation techniques using NiFi
- Partitioning and bucketing data for efficient querying
- Analyzing flight delays, cancellations, and diversions
- Visualizing aviation data insights using dashboards
Recommendation System
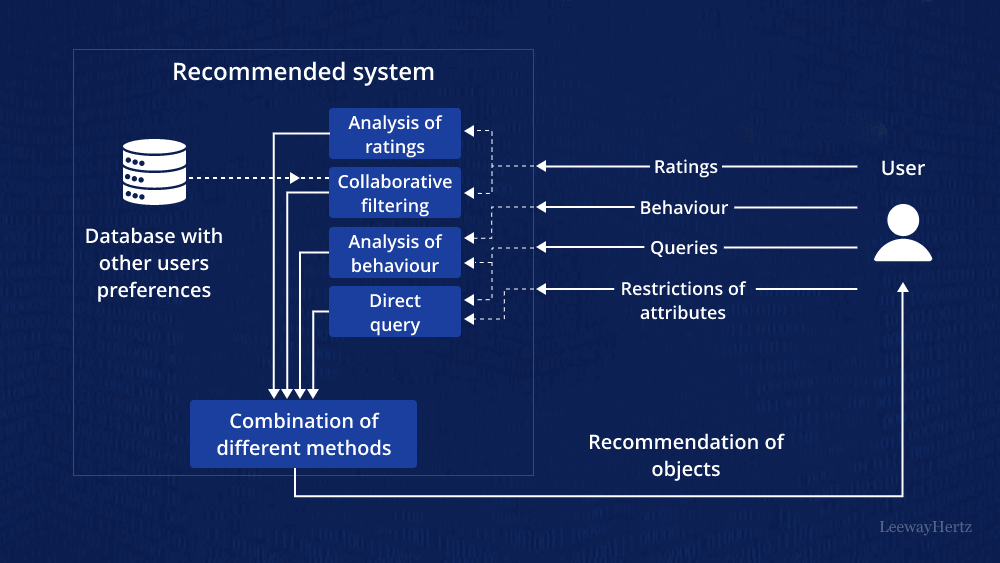
Project Overview:
Create a basic recommendation system that suggests items to users based on their past behavior or similar user profiles. This project introduces machine learning concepts in a practical context. You will use a dataset of user interactions with items, such as ratings, purchases, or clicks, to train a recommendation model.
Quick Guide:
- Gather historical user interaction data, including ratings, purchases, and clicks, from your dataset.
- Choose a recommendation algorithm, such as collaborative filtering or matrix factorization, and implement it using Python libraries like scikit-learn or TensorFlow.
- Train your model on the user interaction data, optimizing it for accuracy in predicting user preferences.
- Evaluate the model's performance using metrics like precision@k and recall@k to ensure effective recommendations.
- Address cold-start issues by incorporating content-based filtering techniques for new users or items.
- Deploy the recommendation system as an API using Flask or FastAPI for real-time predictions.
Technologies Used:
- Python (scikit-learn, TensorFlow, Pandas)
- Matrix factorization algorithms
- Neighborhood-based collaborative filtering
- Flask or FastAPI for model deployment
Skills Learned:
- Understanding recommendation algorithms and their trade-offs
- Implementing machine learning models for recommendation tasks
- Evaluating model performance using appropriate metrics
- Handling cold-start problems and incorporating content-based filtering
- Deploying recommendation models as a service for real-time predictions
Log Analysis Tool
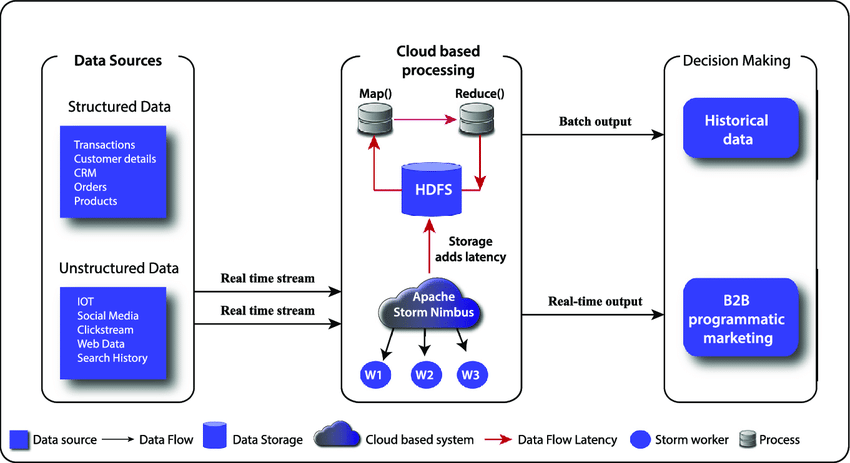
Project Overview:
Build a tool that analyzes log files from web servers or applications to provide insights into user behavior or system performance. This project enhances your ability to work with unstructured data.
Quick Guide:
- Install the ELK stack on your system for log management and analysis.
- Configure Logstash pipelines to define how logs will be ingested, parsed, and transformed into structured formats.
- Set up Elasticsearch indices to store logs efficiently, allowing for quick search and retrieval operations.
- Write scripts in Python to preprocess log files before sending them to Logstash for ingestion.
- Create visualizations in Kibana, building dashboards that display key metrics and trends from your log data.
- Implement security measures, such as role-based access control, to protect sensitive log information while ensuring compliance with privacy standards.
Technologies Used:
- ELK Stack (Elasticsearch, Logstash, Kibana)
- Python for log parsing and transformation
- Logstash configuration files for log processing
- Elasticsearch indices and mappings for data storage
- Kibana for data exploration and visualization
Skills Learned:
- Log file parsing and transformation techniques
- Elasticsearch indexing and querying for large datasets
- Creating Kibana dashboards and visualizations
- Implementing security measures for log data
- Pattern recognition and anomaly detection in log data
Conclusion
Diving into these projects not only sharpens your technical skills but also makes your resume stand out by showing your hands-on experience. Showcasing different projects proves your ability to handle real-world challenges, making you more attractive to companies looking for data engineers.
With each skill you learn with every project, you will be learn new skills and will be ready to take on complex data engineering problems.
Comments (0)